Explain about Data Cleaning
Steps of Data Cleaning
While the techniques used for data cleaning may vary according to the types of data your company stores, you can follow these basic steps to cleaning your data, such as:
1. Remove duplicate or irrelevant observations
Remove unwanted observations from your dataset, including duplicate observations or irrelevant observations. Duplicate observations will happen most often during data collection. When you combine data sets from multiple places, scrape data, or receive data from clients or multiple departments, there are opportunities to create duplicate data. De-duplication is one of the largest areas to be considered in this process. Irrelevant observations are when you notice observations that do not fit into the specific problem you are trying to analyze.
For example, if you want to analyze data regarding millennial customers, but your dataset includes older generations, you might remove those irrelevant observations. This can make analysis more efficient, minimize distraction from your primary target, and create a more manageable and performable dataset.
2. Fix structural errors
Structural errors are when you measure or transfer data and notice strange naming conventions, typos, or incorrect capitalization. These inconsistencies can cause mislabeled categories or classes. For example, you may find "N/A" and "Not Applicable" in any sheet, but they should be analyzed in the same category.
3. Filter unwanted outliers
Often, there will be one-off observations where, at a glance, they do not appear to fit within the data you are analyzing. If you have a legitimate reason to remove an outlier, like improper data entry, doing so will help the performance of the data you are working with.
However, sometimes, the appearance of an outlier will prove a theory you are working on. And just because an outlier exists doesn't mean it is incorrect. This step is needed to determine the validity of that number. If an outlier proves to be irrelevant for analysis or is a mistake, consider removing it.
4. Handle missing data
You can't ignore missing data because many algorithms will not accept missing values. There are a couple of ways to deal with missing data. Neither is optimal, but both can be considered, such as:
- You can drop observations with missing values, but this will drop or lose information, so be careful before removing it.
- You can input missing values based on other observations; again, there is an opportunity to lose the integrity of the data because you may be operating from assumptions and not actual observations.
- You might alter how the data is used to navigate null values effectively.
5. Validate and QA
At the end of the data cleaning process, you should be able to answer these questions as a part of basic validation, such as:
- Does the data make sense?
- Does the data follow the appropriate rules for its field?
- Does it prove or disprove your working theory or bring any insight to light?
- Can you find trends in the data to help you for your next theory?
- If not, is that because of a data quality issue?
Because of incorrect or noisy data, false conclusions can inform poor business strategy and decision-making. False conclusions can lead to an embarrassing moment in a reporting meeting when you realize your data doesn't stand up to study. Before you get there, it is important to create a culture of quality data in your organization. To do this, you should document the tools you might use to create this strategy.
Methods of Data Cleaning
There are many data cleaning methods through which the data should be run. The methods are described below:
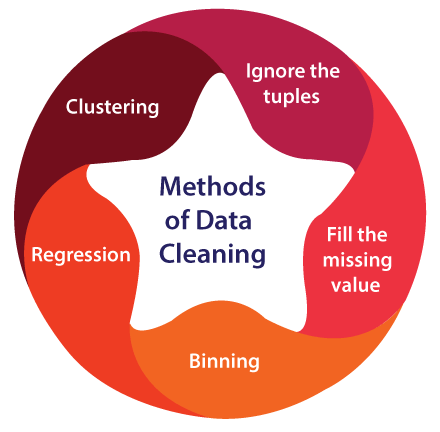
- Ignore the tuples: This method is not very feasible, as it only comes to use when the tuple has several attributes is has missing values.
- Fill the missing value: This approach is also not very effective or feasible. Moreover, it can be a time-consuming method. In the approach, one has to fill in the missing value. This is usually done manually, but it can also be done by attribute mean or using the most probable value.
- Binning method: This approach is very simple to understand. The smoothing of sorted data is done using the values around it. The data is then divided into several segments of equal size. After that, the different methods are executed to complete the task.
- Regression: The data is made smooth with the help of using the regression function. The regression can be linear or multiple. Linear regression has only one independent variable, and multiple regressions have more than one independent variable.
- Clustering: This method mainly operates on the group. Clustering groups the data in a cluster. Then, the outliers are detected with the help of clustering. Next, the similar values are then arranged into a "group" or a "cluster".
Process of Data Cleaning
The following steps show the process of data cleaning in data mining.
- Monitoring the errors: Keep a note of suitability where the most mistakes arise. It will make it easier to determine and stabilize false or corrupt information. Information is especially necessary while integrating another possible alternative with established management software.
- Standardize the mining process: Standardize the point of insertion to assist and reduce the chances of duplicity.
- Validate data accuracy: Analyze and invest in data tools to clean the record in real-time. Tools used Artificial Intelligence to better examine for correctness.
- Scrub for duplicate data: Determine duplicates to save time when analyzing data. Frequently attempted the same data can be avoided by analyzing and investing in separate data erasing tools that can analyze rough data in quantity and automate the operation.
- Research on data: Before this activity, our data must be standardized, validated, and scrubbed for duplicates. There are many third-party sources, and these Approved & authorized parties sources can capture information directly from our databases. They help us to clean and compile the data to ensure completeness, accuracy, and reliability for business decision-making.
- Communicate with the team: Keeping the group in the loop will assist in developing and strengthening the client and sending more targeted data to prospective customers.
Usage of Data Cleaning in Data Mining
Here are the following usages of data cleaning in data mining, such as:
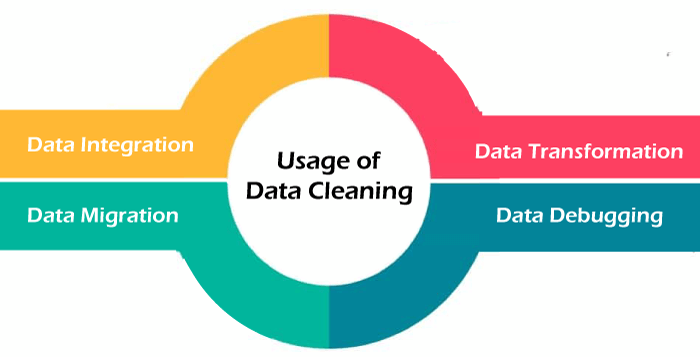
- Data Integration: Since it is difficult to ensure quality in low-quality data, data integration has an important role in solving this problem. Data Integration is the process of combining data from different data sets into a single one. This process uses data cleansing tools to ensure that the embedded data set is standardized and formatted before moving to the final destination.
- Data Migration: Data migration is the process of moving one file from one system to another, one format to another, or one application to another. While the data is on the move, it is important to maintain its quality, security, and consistency, to ensure that the resultant data has the correct format and structure without any delicacies at the destination.
- Data Transformation: Before the data is uploaded to a destination, it needs to be transformed. This is only possible through data cleaning, which considers the system criteria of formatting, structuring, etc. Data transformation processes usually include using rules and filters before further analysis. Data transformation is an integral part of most data integration and data management processes. Data cleansing tools help to clean the data using the built-in transformations of the systems.
- Data Debugging in ETL Processes: Data cleansing is crucial to preparing data during extract, transform, and load (ETL) for reporting and analysis. Data cleansing ensures that only high-quality data is used for decision-making and analysis.
For example, a retail company receives data from various sources, such as CRM or ERP systems, containing misinformation or duplicate data. A good data debugging tool would detect inconsistencies in the data and rectify them. The purged data will be converted to a standard format and uploaded to a target database.
Characteristics of Data Cleaning
Data cleaning is mandatory to guarantee the business data's accuracy, integrity, and security. Based on the qualities or characteristics of data, these may vary in quality. Here are the main points of data cleaning in data mining:
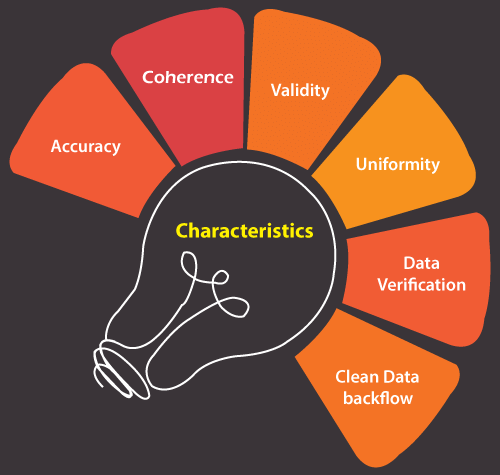
- Accuracy: All the data that make up a database within the business must be highly accurate. One way to corroborate their accuracy is by comparing them with different sources. If the source is not found or has errors, the stored information will have the same problems.
- Coherence: The data must be consistent with each other, so you can be sure that the information of an individual or body is the same in different forms of storage used.
- Validity: The stored data must have certain regulations or established restrictions. Likewise, the information has to be verified to corroborate its authenticity.
- Uniformity: The data that make up a database must have the same units or values. It is an essential aspect when carrying out the Data Cleansing process since it does not increase the complexity of the procedure.
- Data Verification: The process must be verified at all times, both the appropriateness and the effectiveness of the procedure. Said verification is carried out through various insistence of the study, design, and validation stages. The drawbacks are often evident after the data is applied in a certain amount of changes.
- Clean Data Backflow: After eliminating quality problems, the already clean data must be replaced by those not located in the original source, so that legacy applications obtain the benefits of these, obviating the need for applications of actions of data cleaning afterward.
Tools for Data Cleaning in Data Mining
Data Cleansing Tools can be very helpful if you are not confident of cleaning the data yourself or have no time to clean up all your data sets. You might need to invest in those tools, but it is worth the expenditure. There are many data cleaning tools in the market. Here are some top-ranked data cleaning tools, such as:
- OpenRefine
- Trifacta Wrangler
- Drake
- Data Ladder
- Data Cleaner
- Cloudingo
- Reifier
- IBM Infosphere Quality Stage
- TIBCO Clarity
- Winpure
Benefits of Data Cleaning
Having clean data will ultimately increase overall productivity and allow for the highest quality information in your decision-making. Here are some major benefits of data cleaning in data mining, such as:
- Removal of errors when multiple sources of data are at play.
- Fewer errors make for happier clients and less-frustrated employees.
- Ability to map the different functions and what your data is intended to do.
- Monitoring errors and better reporting to see where errors are coming from, making it easier to fix incorrect or corrupt data for future applications.
- Using tools for data cleaning will make for more efficient business practices and quicker decision-making.




No comments:
Post a Comment